ETL vs ELT – 5 Key Differences: Comprehensive Guide – The principal difference between Extract-Load-Transform (ELT) and Extract-Transform-Load (ETL) is in the order of operations. ETL stands for extract, transform, load, meaning that the process involves extracting data from its source first, followed by transformation into a usable format in a staging area, and finishing with the transfer of the usable data to a storage repository where it can be accessed for analysis.
ETL vs ELT – 5 Key Differences:
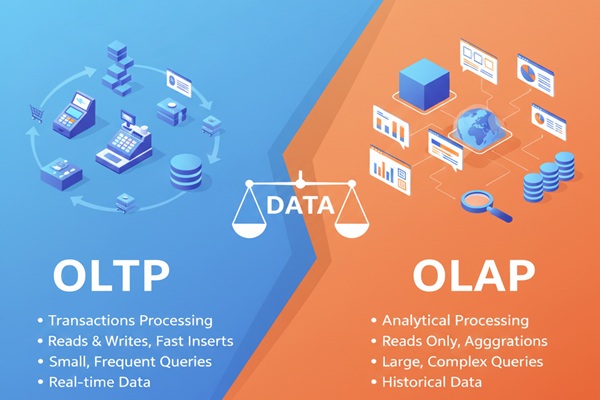
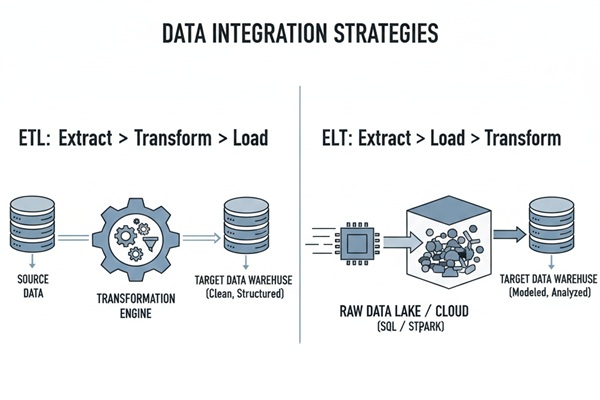
- ETL stands for Extract, Transform, and Load. ELT means Extract, Load, and Transform. Both are processes for data integration.
- Using the ETL method, data moves from the data source to staging, then into the data warehouse.
- ELT leverages the data warehouse to do basic transformations. There is no need for data staging.
- ETL can help with data privacy and compliance by cleaning sensitive and secure data before loading it into the data warehouse.
- ETL can perform sophisticated data transformations and can be more cost-effective than ELT
What is Data Integration?
Data integration is the process by which data from multiple sources is combined and made available in a unified and cohesive manner. Its primary aim is to offer a holistic view, allowing businesses to derive actionable insights, streamline operations, and make decisions based on data rather than theory.
What is ELT (extract, load, transform)?
ELT (Extract, Load, Transform) is a more recent approach where raw data is directly transferred to the data warehouse, and transformations occur within its confines, bypassing the need for intermediary staging processes.
ELT decouples the transformation and load stages, ensuring that a coding error (or other error in the transformation stage) does not halt the migration effort.
The ELT approach enables faster implementation than the ETL process, though the data is messy once it is moved. The transformation occurs after the load function, preventing the migration slowdown that can occur during this process.
What is ETL (extract, transform, load)?
ETL is the traditional technique of extracting raw data, transforming it as required for the users and storing it in data warehouses. ELT was later developed, with ETL as its base. The three operations in ETL and ELT are the same, except that their order of processing is slightly different. This change in sequence was made to overcome some drawbacks.
Extract: It is the process of extracting raw data from all available data sources such as databases, files, ERP, CRM or any other.
Transform: The extracted data is immediately transformed as required by the user.
Load: The transformed data is then loaded into the data warehouse from where the users can access it.
- Comprehensive automation and ease-of-use functions that can automate the entire data flow and make recommendations on rules for the extract, transform and load process.
- A visual drag-and-drop interface used for specifying rules and data flows.
- Support for complex data management to assist with complex calculations, data integrations and string manipulation.
- Security and compliance that encrypt sensitive data — both in motion and at rest — and are certified compliant with industry or government regulations like HIPAA and GDPR. This provides a more secure way to encrypt, remove or mask specific data fields to protect client’s privacy.
Drawbacks of ETL:
- Expensive to Implement and Maintain: ETL isn’t a walk in the park. Implementing it can take months, with continuous tweaks following suit. This complexity often forces businesses to hire specialists for the job.
- Rigid-in-Nature: ETL is structured. Transformations occur in a staging area between the source and destination, ensuring data format consistency but hindering the rapid processing of vast data volumes. Also, it demands that analysts predefine their data usage strategies, which can lead to format-related complications.
- Slow to Provide Fresh Data: ETL lags in delivering fresh data. Transformations precede data loading, making ETL less agile in managing today’s data influx. Often, ETL processes get relegated to nighttime slots, denying analysts access to real-time data.
- Low in Visibility: Users see only the transformed, loaded data, not the raw version. This myopic view can lead to misinterpretations, especially if data gets reshaped during transformations.
The Biggest Advantages of ELT:
You don’t have to develop complex ETL processes before data ingest, and it saves developers and BI analysts time when dealing with new information.
The primary advantage of ELT over ETL relates to flexibility and ease of storing new, unstructured data. With ELT, you can save any type of information—even if you don’t have the time or ability to transform and structure it first—providing immediate access to all of your information whenever you want it.
High Speed:
When it comes to data availability, ELT is the faster option. ELT allows all the data to go into the system immediately, and from there, users can determine the exact data they need to transform and analyze.
Low Maintenance:
With ELT, users generally won’t need a “high-touch” maintenance plan. Since ELT is cloud-based, it utilizes automated solutions instead of relying on the user to initiate manual updates.
Quicker Loading:
Because the transformation step doesn’t occur until after the data has entered the warehouse, it cuts down on the time it takes to load the data into its final location. There’s no need to wait for the data to be cleansed or otherwise modified, and it only needs to go into the target system once.
Similarities Between ETL and ELT
- Data Extraction: Both processes begin by extracting raw data from multiple sources like databases, files, SaaS applications, or IoT devices. This data can be structured, semi-structured, or unstructured.
- Data Transformation: While the timing of transformation differs, both ETL and ELT involve transforming the extracted data into a format that aligns with the target system’s requirements. This ensures data is clean, accurate and ready for analysis.
- Data Loading: Both methods ultimately load the processed data into a data warehouse or data lake, providing a central repository where the data can be accessed and analyzed.
- Unified Data Repository: Both processes help create a single source of truth, ensuring that enterprise data is consistent, accurate and up-to-date for decision-making.
ETL Use Cases:
- Legacy Systems: ETL fits seamlessly with older systems that may not be equipped to handle on-site data transformations, offering a dedicated transformation process.
- Smaller Datasets: When dealing with relatively smaller data volumes that require intricate transformations, ETL can prove efficient.
- High Data Security Needs: ETL’s structured and controlled transformation process can offer enhanced security, especially when handling sensitive data.
- Diverse Data Sources: When integrating data from multiple disparate sources, ETL’s transformation phase can harmonize and cleanse data before loading.
ELT Use Cases:
- Modern Data Warehouses: Cloud-based and advanced warehousing solutions like Snowflake or BigQuery can leverage ELT’s potential, performing transformations after data loading.
- Large Data Volumes: ELT can swiftly handle vast amounts of data, leveraging the scalability of modern warehouses.
- Real-time Analytics: Since ELT involves faster initial loading, it can support near-real-time analytics, transforming data on-the-go.
- Adaptable Data Processing: ELT’s flexibility caters to both structured and unstructured data, providing analysts with the liberty to mold data as required.
ETL vs ELT: Comparison
|
Category |
ETL |
ELT |
|
Definition |
Data is extracted from a source system, transformed on a secondary processing server, and loaded into a destination system. |
Data is extracted from a source system, loaded into a destination system, and transformed inside the destination system. |
|
Extract |
Raw data is extracted using API connectors.
|
Raw data is extracted using API connectors. |
|
Transform |
Raw data is transformed on a processing server.
|
Raw data is transformed inside the target system.
|
|
Load |
Transformed data is loaded into a destination system.
|
Raw data is loaded directly into the target system.
|
|
Speed |
ETL is a time-intensive process; data is transformed before loading into a destination system.
|
ELT is faster by comparison; data is loaded directly into a destination system, and transformed in-parallel.
|
|
Code-Based Transformations |
Performed on secondary server. Best for compute-intensive transformations & pre-cleansing.
|
Transformations performed in-database; simultaneous load & transform; speed & efficiency.
|
|
Maturity |
Modern ETL has existed for 20+ years; its practices & protocols are well-known and documented.
|
ELT is a newer form of data integration; less documentation & experience.
|
|
Privacy |
Pre-load transformation can eliminate PII (helps for HIPPA).
|
Direct loading of data requires more privacy safeguards. |
|
Maintenance |
Secondary processing server adds to the maintenance burden. |
With fewer systems, the maintenance burden is reduced. |
|
Costs |
Separate servers can create cost issues. |
Simplified data stack costs less. |
|
Requires |
Data is transformed before entering destination system; therefore raw data cannot be required. |
Raw data is loaded directly into destination system and can be required endlessly. |
|
Data Lake Compatibility |
No, ETL does not have data lake compatibility. |
Yes, ELT does have data lake compatibility. |
|
Data Output |
Structured (typically). |
Structured, semi-structured, unstructured. |
|
Data Volume |
Ideal for small data sets with complicated transformation requirements. |
Ideal for large datasets that require speed & efficiency. |
Choosing Between ELT and ETL
The choice between ETL and ELT depends on our specific needs and requirements.
- ETL works well for smaller datasets and structured data where the data needs to be transformed immediately. It often requires special hardware and can be less flexible when handling large amounts of data.
- ELT is better for large datasets and unstructured or non-relational data. It is more flexible and cost-effective, especially with cloud-based data solutions. With ELT, we can store raw data and transform it as needed.
Frequently Asked Questions about ETL vs. ELT:
1. What is ETL, and how does it work?
ETL (Extract, Transform, Load) is a data integration process that extracts data from source systems, transforms it on a staging server or data warehouse to meet specific requirements, and then loads it into a data warehouse. It’s best for structured data, smaller datasets, or when compliance and data privacy are critical.
2. What is ELT, and how is it different from ETL?
ELT (Extract, Load, Transform) directly loads raw data into a data warehouse and performs transformations within the warehouse itself. ETL process leverages modern cloud-native tools, offering faster ingestion, scalability, and support for unstructured data types. Unlike ETL, it retains raw data for historical analysis.
3. Why is ELT better suited for modern data environments?
ELT thrives in cloud-based environments because it uses the warehouse’s native processing power. It supports high data velocity, large volumes, and diverse data types (structured, semi-structured, and unstructured). This makes it ideal for real-time analytics and scalable workflows.
4. When should I choose ETL over ELT?
When
- You’re working with legacy systems.
- You need rigorous pre-load data transformations for compliance.
- Your datasets are relatively small and structured.
Then ETL
End.
5. When should I choose ELT over ETL?
When:
- You’re leveraging modern cloud warehouses like Snowflake, BigQuery, or Redshift.
- You need to process vast amounts of raw data for agile analytics.
- You require real-time or near-real-time insights.
Then ELT
End.
6. Can I use ETL and ELT together?
Yes, some organizations combine both methods. ETL may handle sensitive or structured data transformations upfront, while ELT processes unstructured or high-volume data within the warehouse.