Understanding SQL query order can help you diagnose why a query won’t run, and even more frequently will help you optimize your queries to run faster.
What is SQL Order of Execution?
SQL order of execution refers to the order in which the different clauses in the query are evaluated. It’s worth understanding because the execution order is usually different from how we write the SQL queries. To take the most simple example, you might think that in the case of SELECT * FROM database, the SELECT is evaluated first, but really the order of execution starts with it’s the FROM clause.
Here is the SQL order of execution. In the next section, we will go through the steps in detail.
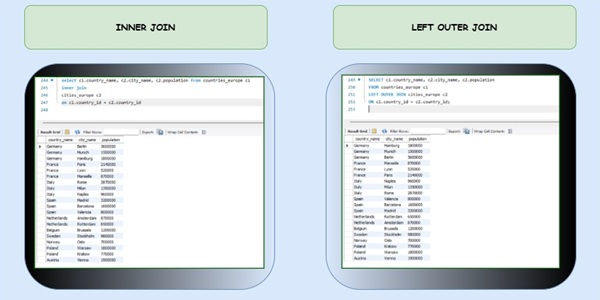
FROM/JOIN: Specifies the tables from which to retrieve data.
WHERE: Filters the rows that meet the condition before grouping.
GROUP BY: Groups rows that share a property.
HAVING: Filters groups based on conditions, applied after grouping.
SELECT: Specifies the columns to retrieve or calculate.
DISTINCT: Removes duplicate rows from the result set.
ORDER BY: Sorts the result set by specified columns.
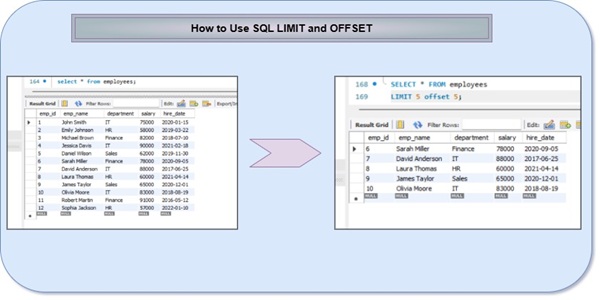
LIMIT: Specifies the maximum number of rows to return.
OFFSET: Specifies how many rows to skip before starting to return rows.
Why SQL Order of Execution is Important?
Performance Optimization: The execution order ensures that operations like filtering and grouping occur before resource-intensive tasks such as sorting.
Data Reduction: Early filtering reduces the data set size for subsequent operations, improving efficiency.
Accurate Results: Incorrect execution order can lead to wrong outcomes.
Debugging Ease: Understanding the sequence helps troubleshoot and fine-tune queries.
- FROM Clause
The FROM clause is where SQL begins processing a query. It identifies the table(s) involved and sets the stage for other operations.
Table and Subquery Processing: The data from the specified table(s) is fetched first. If the query includes subqueries, they are evaluated during this step.
JOIN Operations: If the query includes a JOIN, SQL combines rows from the involved tables based on the specified conditions. Technically, the JOIN operation is part of the FROM clause.
Data Preparation: This step filters out unnecessary data and creates a smaller, intermediate dataset for further processing in subsequent clauses.
Temporary Tables: SQL may create temporary tables internally for handling complex operations.
- WHERE Clause
After the table data on which other operations take place is processed by JOIN and FROM clause, WHERE clause is evaluated.
WHERE clause filters the rows based on conditions from the table evaluated by the FROM clause.
This WHERE clause discards rows that don’t satisfy the conditions, thus reducing the rows of data that need to be processed further in other clauses. - GROUP BY Clause
If a query includes a GROUP BY clause, it is executed after filtering (via the WHERE clause). This step organizes the data into groups based on the distinct values in the specified column(s).
Data Grouping: Rows with the same value in the GROUP BY column are grouped together.
Row Reduction: The number of rows is reduced to match the number of unique values in the grouping column(s).
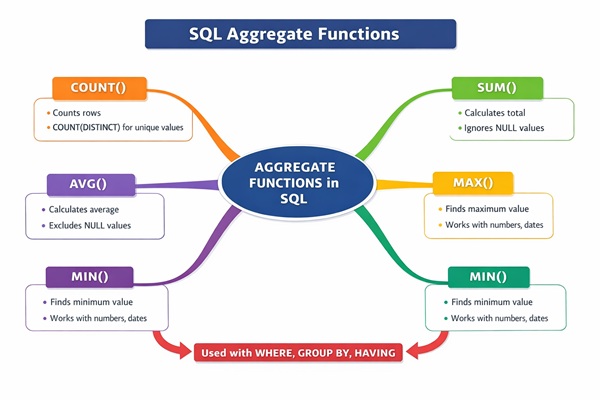
Aggregate Functions: Aggregate calculations like SUM, AVG, COUNT, etc., are applied to each group to produce meaningful insights.
- HAVING Clause
If a query includes a GROUP BY clause, the HAVING clause is evaluated immediately afterward. While it is optional, the HAVING clause plays a similar role to the WHERE clause, but specifically filters the grouped data created by GROUP BY.
Purpose: It applies conditions to aggregated results (like totals or averages) rather than individual rows.
Filtering Groups: Groups that don’t meet the specified condition are excluded, reducing the data further for subsequent operations.
Difference from WHERE: WHERE filters rows before grouping, while HAVING filters groups after aggregation.
- SELECT Clause
The SELECT clause is executed after the GROUP BY and HAVING clauses. This is where the actual data to be displayed is defined.
Purpose: It computes expressions such as arithmetic operations, aggregate functions (e.g., SUM, COUNT), or custom calculations, and applies aliases for easier readability.
Optimized Execution: By this stage, filtering and grouping operations have significantly reduced the dataset size, ensuring computations are efficient and focused only on the relevant data.
- DISTINCT Clause
The DISTINCT clause is executed after expressions and aliases in the SELECT clause. Its primary purpose is to filter out duplicate rows, ensuring the final output contains only unique rows.
Purpose: Removes duplicate records, making the result set concise and precise.
Execution Order: It operates on the dataset generated after computations in the SELECT clause, meaning the output has already been processed for calculations or aliases.
- ORDER BY Clause
After all previous clauses have been executed, the ORDER BY clause is used to sort the final result set. It organizes the data based on specified column(s) in either ascending (default) or descending order.
Execution Order: The ORDER BY clause comes last in the query execution, working on the final dataset produced by previous clauses.
Left Associative: Sorting is performed based on the first specified column, and if there are duplicates, the second column is used for further sorting, and so on.
- LIMIT/OFFSET Clause
Finally, after all the previous clauses have been executed and the data is ordered, the LIMIT and OFFSET clauses are applied to restrict the number of rows returned.
LIMIT: Specifies the maximum number of rows to return.
OFFSET: Skips the specified number of rows before beginning to return the result set
| Clause | Function |
| FROM / JOIN | When you write any query, SQL starts by identifying the tables for the data retrieval and how they are connected. |
| WHERE | It acts as a filter; it filters the record based on the conditions specified by the users. |
| GROUP BY | The filtered data is grouped based on the specified condition. |
| HAVING | It is similar to the WHERE clause but applied after grouping the data. |
| SELECT | The clause selects the columns to be included in the final result. |
| DISTINCT | Remove the duplicate rows from the result. Once you apply this clause, you are only left with distinct records. |
| ORDER BY | It sorts the results (increasing/decreasing/A->Z/Z->A) based on the specified condition. |
| LIMIT / OFFSET | It determines the number of records to return and from where to start. |
Customers Table
| customer_id | first_name | last_name | age | country |
|---|---|---|---|---|
| 1 | John | Doe | 31 | USA |
| 2 | Robert | Luna | 22 | USA |
| 3 | David | Robinson | 22 | UK |
| 4 | John | Reinhardt | 25 | UK |
| 5 | Betty | Doe | 28 | UAE |
Orders Table
| order_id | item | amount | customer_id |
|---|---|---|---|
| 1 | Keyboard | 400 | 4 |
| 2 | Mouse | 300 | 4 |
| 3 | Monitor | 12000 | 3 |
| 4 | Keyboard | 400 | 1 |
| 5 | Mousepad | 250 | 2 |
Problem Statement: Find the amount spent by each customer in the USA.
SELECT Customers.first_name, Customers.last_name, SUM(Orders.Amount) as AmountFROM CustomersJOIN Orders ON Customers.customer_id = Orders.customer_idWHERE Customers.country = 'USA'GROUP BY Customers.first_name, Customers.last_nameORDER BY Amount DESC;
Output
| first_name | last_name | Amount |
|---|---|---|
| John | Doe | 400 |
| Robert | Luna | 250 |
Explanation
- FROM and JOIN: We start by identifying the ‘Customers‘ and ‘Orders‘ tables and joining them on ‘customer_id‘.
- WHERE: It will filter the record to include only those where ‘country‘ = ‘USA‘.
- GROUP BY: Group the remaining entries (after filtering by WHERE clause) by ‘first_name‘ and ‘last_name‘.
- SELECT: SELECT the ‘first_name‘, ‘last_name‘, and the sum of ‘Amount‘ for each group.
- ORDER BY: Finally, the result is sorted by ‘Amount‘ in descending order.
Window Functions (OVER()):
-
Executed after
WHERE,GROUP BY,HAVING, but within theSELECTorORDER BYclause. -
Comes after aggregation (but before final sort).
-
Allowed in
SELECTandORDER BYclauses.
Subqueries:
-
Executed first, i.e., before the outer query (depending on their location).
-
Types:
-
In
FROM→ Treated as a derived table. -
In
WHERE/SELECT→ Evaluated per row or once, depending on context.
-
CASE WHEN … THEN … END:
-
Used inside
SELECT,WHERE,ORDER BYetc. -
Evaluated during
SELECTorORDER BYstage.
UNION / UNION ALL:
-
Combines the results of two full queries.
-
Each individual query follows the full logical execution order described above.
-
UNIONremoves duplicates;UNION ALLdoes not.
Summary Order :
-
Subqueries (inner-most first)
-
FROM
-
JOIN
-
WHERE
-
GROUP BY
-
HAVING
-
SELECT
-
Includes CASE, window functions
-
-
DISTINCT
-
ORDER BY
-
LIMIT/OFFSET
-
UNION / UNION ALL (combines two full result sets)